Your browser doesn't support the features required by impress.js, so you are presented with a simplified version of this presentation.
For the best experience please use the latest Chrome or Safari browser. Firefox 10 (to be released soon) will also handle it.
Machine Learning
(Ruby edition)
Ed Toro
Miami Ruby Brigade, CareCloud, 2012-09-24

How do you teach a machine to learn?
- Input.
How do you teach a machine to learn?
- Input.
- Data structures.
[[1,2,3], [4,5,6], [7,8,9]]
How do you teach a machine to learn?
- Input.
- Data structure.
- Reduction.

How do you teach a machine to learn?
- Input.
- Data structure.
- Reduction.
- Inference.

Input: visitors to a "guess your weight" site

Data Structure: you can't record everything about a visitor
Reduction: you can't guess every value you've recorded
Average weight of all previous visitors: 150lbs
Inference: What can we infer from the data?
- The next visitor probably weighs as much as the average of all previous visitors.
- The next male visitor probably weighs as much as the average of all previous male visitors.
- etc...
Ruby Data Structures
- arrays: [1,2,3,4]
- hashes: {haterz:1, lovahz:2, playahz:3}
- nested combinations of the above:
[1, [2,3], {playa: 'hatah'}] - serialized storage: databases, files, NoSQL, etc.
Request/Response Cycle - Feedback
- Receive user request for data
- Infer a response based on some prior knowledge reduction
- Receive user request with feedback
- Add the feedback to the existing body of knowledge
- Reduce
Request/Response Cycle - Training
- Collect user data
- Build data structures
- Reduce
- Receive user request
- Infer a response based on prior knowledge and training
Simple example: Inference by mean average
- Input & Data Structure
knowledge =
retrieve_and_deserialize_data_from_datasource()
knowledge << user_weight
- Reduction & Inference
sum = knowledge.inject(:+).to_f
reduction = sum / knowledge.size
response.inference = reduction
The mean average "learns". When it's wrong, it adapts.
Faster simple example: Inference by mean average
- Reduction & Inference
prev_sum, prev_size = cache.get(:key)
new_sum = prev_sum + user_weight
new_size = prev_size + 1
cache.put(:key, [new_sum, new_size])
new_mean = new_sum / new_size
response.inference = new_mean
The knowledge set is big data. The ability to do incremental updates is key to machine learning performance.
Another simple example: genetic algorithm
best_guess = retrieve_most_successful_guess()
response.inference = best_guess
if we_guessed_correctly()
best_guess.success += 1
else
best_guess.success -= 1
end
best_guess.save()
Use whichever guess is the most successful "in the wild". The visitor has to let us know if we were correct.
Complex example: neural network
- Input & Data Structure
nodes = retrieve()
nodes.default = 0
nodes[user_data] = nodes[user_data] + 1
- Reduction & Inference
reduction = nodes.sort_by {|user_data, count| count}[0]
inference = reduction[0]
nodes is a frequency chart. If 200lbs. appears twice, nodes[200] is 2. The strongest node wins. The reduction is the mode average of the knowledge set.
This can get really complicated...
- K-Means Clustering
- i.e. sorting M&Ms by color
- clusters inputs into k buckets identified by k different mean averages
- infers the mean value of the bucket including or closest to the input
- Bayes Classification
- Thomas Bayes' theorem
- given some known probabilities, calculate some unknown probability, and infer from it
- P(A|B) = P(B|A) * P(A) / P(B)
The machine learning algorithms have already been written for you
Stop inventing "new" machine learning algorithms for your site. Just pick one!

OMGWTF! There are so many. Which one do I pick?

All of the above!
The Meta-Learning Algorithm
best_learning_algo = retrieve_most_successful_algorithm()
response.inference = best_learning_algo.guess(user_data)
if we_guessed_correctly()
best_learning_algo.success += 1
else
best_learning_algo.success -= 1
end
best_learning_algo.save()
This is the genetic algorithm applied to learning algorithms. Implement them all, then pick the most successful one.
The "best"? The "most successful"?

A "Bestest" algorithm - a weighted random choice
algos = { kmeans: 50, mean: 25, bayes: 20, neural: 5 }
sum = algos.values.inject(:+)
needle = rand(sum)
algos.sort_by{ |key,val| -val }.each do |algo|
needle -= algo[1]
if needle < 0
#break or return
end
end
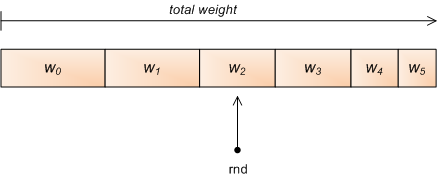
FAIL! All weights must be > 0 for that to work.
success = [0, success - 1].max

The algorithms may be free (or at least "cloud cheap"), but the data isn't.
Stop worrying about algorithms. It's the data, stupid!
There are two types of data
- Content
- Collaborative
- E-Commerce
- price
- color
- size
- Music
- genre
- beats-per-minute
- tempo
- Site pages
- main keywords
- length
It's data that describes the content on your site. When two pieces of content are similar, we infer a user who likes one will also like the other.
- gender
- age
- location
- favorite content
- friends
It's data describing the visitors to your site. When two visitors are similar, we infer that they'll like the same stuff.
Data needs to be numerical so you can do math on it.
- gender: { 'male': 0, 'female': 1, 'other': 2}
- employed: { 'false': 0, 'true': 1}
When possible, "numerification" should be meaningful. Labels that are related map to numbers that are closer.
- language: { 'en': 0, 'en-us': 1, 'en-gb': 2, 'es': 10, 'es-es': 11, 'es-mx': 12 }
- education: { 'some high-school': 0, 'high-school': 1, 'some college': 2, 'college': 3, 'masters': 4}
The fully numerified description of a piece of content or a visitor is its "DNA".
['gender', 'age', 'location_lat', 'location_long']
becomes
[0, 30, 26, -80]
The similarity score between two pieces of content is the "distance" between these two "points". The lower the score, the more similar the content.
# male, 30yo, Miami (lat, long)
person1 = [0, 30, 25.8, -80.2]
# female, 25yo, Ft. Lauderdale (lat, long)
person2 = [1, 25, 26.1, -80.1]
score = Math.sqrt(p1.zip(p2).map{|a,b| a-b}.map{|d| d*d}.reduce(:+))
# score is approx 5
This magic formula represents the Euclidean distance as given by the Pythagorean theorem.
score2 = (a1-a2)2 + (b1-b2)2 + (c1-c2)2 + (d1-d2)2
Performance
Machine learning is a "big data" problem. Learn how those guys solve these kinds of problems.
- MapReduce - I called it "reduction" for a reason
- Apache Pig
- Apache Hadoop
Say your website has 1 million songs. Imagine a grid with 106 rows and 106 columns. How many pairwise comparisons does that produce?
106 * 106 = 1012 (1 trillion*!)
*actually more like half a trillion if you ignore A vs. A and assume (A vs. B) = (B vs. A), but still...
Now add a collaborative analysis: every user is compared to every other user. More input!
- How long does it take to calculate all those scores?
- How many numbers make up each song's "DNA"?
- How many numbers make up each song's "DNA"?
- Where do you store the results?
- Hey database guy! You got room for 1 trillion rows lying around somewhere?
- Hey database guy! You got room for 1 trillion rows lying around somewhere?
- How quickly can you lookup a result at runtime?
- e.g. Generate the top 5 most similar songs.
- e.g. Generate the top 5 most similar songs.
- How often do you need to update your library?
- e.g. If you update weekly, but it takes two weeks to structure and reduce the data, you'll never catch up.
- e.g. If you update weekly, but it takes two weeks to structure and reduce the data, you'll never catch up.
Cluster the songs so that similar songs get grouped together. All songs in the same cluster are equally similar to each other.
e.g. If you have 1 million songs, group them into chunks of 100 songs each, leaving 10,000 song-clusters.
Clustering algorithms:
- hierarchical
- k-means
- self-organizing maps
Storage: You only have to store 10,000 cluster ids instead of 1 trillion sim scores.
Lookup: To find the songs most similar to any given song, randomly select other songs from the same cluster.
Updates: Calculate "average DNAs" for each cluster. Place the new song in the cluster whose average DNA is closest. For the 1,000,001st song, that's 10,000 comparisons instead of 1 million.
Johnny 5 can learn!

Thanks for listening!
@eddroid
github.com/eddroid
Google Images:
- http://www.schoolsignsonline.com.au/contents/media/34502-reduce-reuse-recycle.gif
- http://i0.kym-cdn.com/photos/images/newsfeed/000/039/080/5008_9c00_420.gif
- http://2.bp.blogspot.com/_g6jnLh81N64/TO48Xn1ZtnI/AAAAAAAAASA/MQHdSg2fQmI/s1600/Walking+skeleton.png
- http://www.coverbrowser.com/image/popular-library/158-1.jpg
- http://cache.jalopnik.com/assets/images/4/2008/06/lego_johnny_five.jpg
- http://www.retroist.com/wp-content/uploads/2011/07/johnny_5_is_alive_by_speedball0o.jpg
- http://www.schoolsignsonline.com.au/contents/media/34502-reduce-reuse-recycle.gif
- http://aux.iconpedia.net/uploads/1442736216.png
- http://blogs.villagevoice.com/runninscared/sstop.jpg
Google Images:
- http://profile.ak.fbcdn.net/hprofile-ak-snc4/162076_149773725075253_7380223_n.jpg
- http://4.bp.blogspot.com/_vd_zVJKziTE/TO_Ow5GbxoI/AAAAAAAAA8U/jbZ7VoM23yw/s400/mandy%2Bp.jpg
- http://obscureinternet.com/wp-content/uploads/Concert-Fail.jpg
http://eli.thegreenplace.net/2010/01/22/weighted-random-generation-in-python/
- http://eli.thegreenplace.net/wp-content/uploads/2010/01/subweight.png
Can I use these images? We beat that SOPA/PIPA thing, right?
- Derived properties (e.g. value entropy)
- Non-Euclidean distances (e.g. Hamming, Manhattan, maximum)
- A user's personal algorithm preferences
- Dimensionality reduction